Project members: Valentin Debranot and Ivan Dokmanić
Despite their ability to serve as excellent signal priors, traditional generative models suffer from a key limitation—these networks can only produce images that are supported on discrete grids. Since natural images are inherently continuous, changes in acquisition hardware can result in images with different resolution, thereby causing any previously trained priors irrelevant.
We recently addressed this problem with FunkNN [1], our novel continuous super-resolution architecture that can take a discrete image as input and super-resolve it to any arbitrary super-resolution. Then we can simply combine FunkNN with any pre-trained discrete convolutional generator to obtain image samples at continuous spatial coordinates.
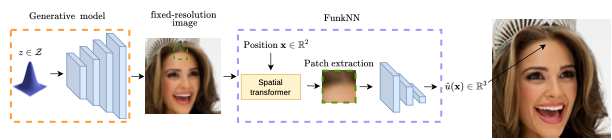
Figure 1. Illustration of FunkNN based continuous generative model pipeline. The generative model (orange) produces a fixed-resolution image that is used to produce the image intensity at any location (blue).
One of the key advantages of FunkNN over prior continuous models [2,3,4] is its effective performance despite significantly lower number of trainable parameters. FunkNN achieves this by using a strong locality constraint inspired from signal processing in its architecture.
Project proposal
Currently, FunkNN performs continuous super-resolution for images in a scale agnostic manner. However, since discrete images can have objects captured at different scales, incorporating this can provide additional gains in super-resolution performance.
In this work, we propose to condition the FunkNN architecture on the input image's scale while maintaining the locality constraints that provide FunkNN its architectural simplicity.
Pre-requisites
This project has a significant coding component. Proficiency in PyTorch/Tensorflow is essential.
Interested students can send an e-mail to Valentin.
References
[1] Amir Khorashadizadeh, Anadi Chaman, Valentin Debarnot, and Ivan Dokmani ́c. Funknn: Neural interpolation for functional generation. 2022.
[2] Y. Chen, S. Liu and X. Wang, "Learning Continuous Image Representation with Local Implicit Image Function," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 8624-8634, doi: 10.1109/CVPR46437.2021.00852.
[3] Emilien Dupont, Yee Whye Teh, and Arnaud Doucet. Generative models as distributions of func- tions. arXiv preprint arXiv:2102.04776, 2021.
[4] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5939–5948, 2019.