We propose a neural PDE solver built entirely from learned coordinate warps: no Fourier layers, no attention, (almost) no convolutions. Our compact 17M-parameter model consistently outperforms Fourier, convolutional, and attention-based baselines across all 16 tested benchmarks from The Well and PDEBench. Scaled to 150M parameters, it outperforms Poseidon-L (628M parameters, pretrained) on compressible Euler, training from scratch with 4× fewer parameters.
Results
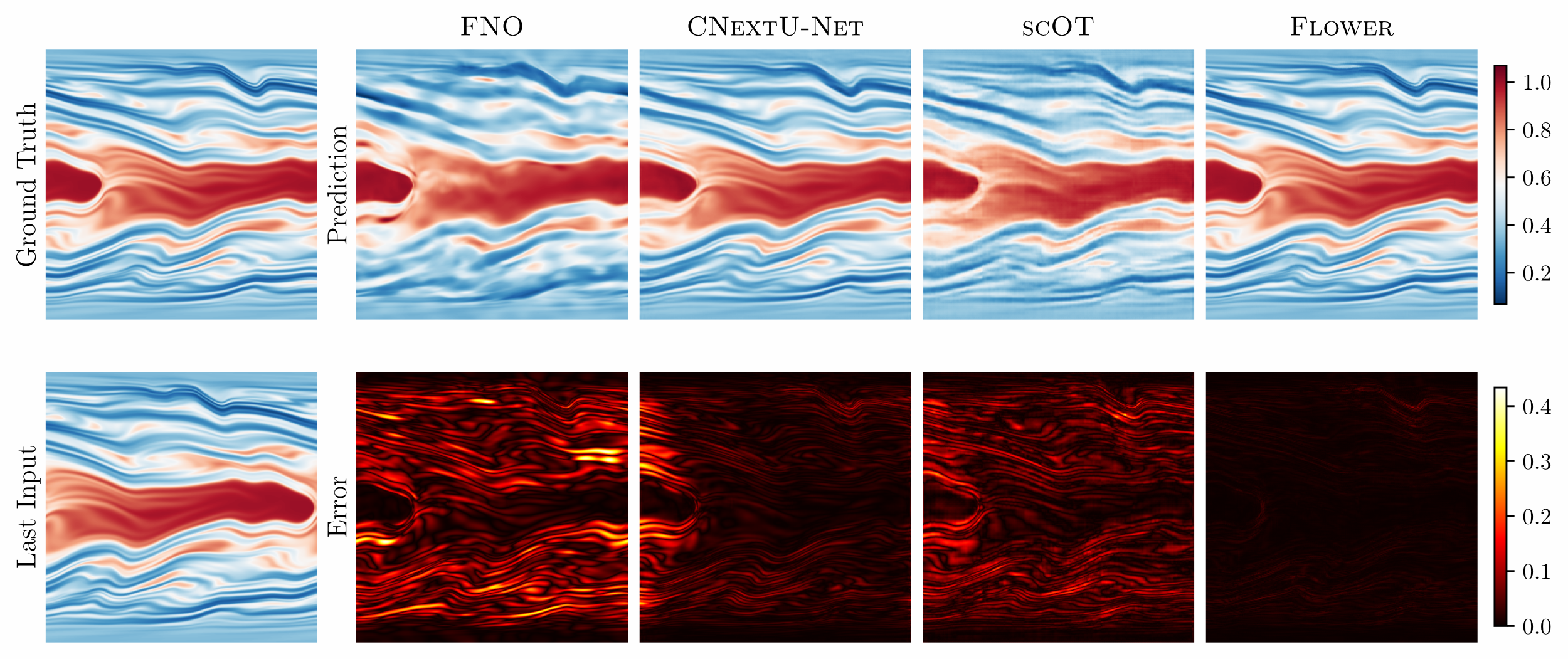
Viscoelastic instability: one-step prediction of the conformation tensor entry Czz. Top row: ground truth and model predictions. Bottom row: last input frame and pointwise errors.
We benchmark on 16 datasets drawn from The Well and PDEBench, covering fluid dynamics, wave propagation, magnetohydrodynamics, 3D flows, and more. Models are compared at roughly equal parameter count (15–20M): FNO, a convolutional U-Net (CNUnet), an attention-based model (scOT), and Flower. Flower achieves the best next-step prediction on every dataset and the best 1:20 rollout on 15 of 16.
| Collection | Dataset | Next-step (VRMSE ↓) | 1:20 Rollout (VRMSE ↓) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FNO | CNUnet | scOT | Flower | FNO | CNUnet | scOT | Flower | ||
| The Well | acoustic_scattering_maze | 0.1454 | 0.0129 | 0.0361 | 0.0064 | 0.4197 | 0.0874 | 0.1996 | 0.0489 |
| active_matter | 0.1749 | 0.0650 | 0.1050 | 0.0249 | 3.2862 | 1.7781 | 4.1055 | 1.3905 | |
| gray_scott_reaction_diffusion | 0.0372 | 0.0188 | 0.0673 | 0.0102 | 0.9125 | 0.3059 | 0.4169 | 0.2074 | |
| MHD_64 | 0.3403 | 0.2062 | — | 0.1165 | 1.3007 | 0.9534 | — | 0.7580 | |
| planetswe | 0.0070 | 0.0027 | 0.0041 | 0.0007 | 0.1316 | 0.0624 | 0.0518 | 0.0187 | |
| post_neutron_star_merger | 0.4452 | 0.3391 | — | 0.3269 | 0.5980 | 0.6529 | — | 0.6223 | |
| rayleigh_benard | 0.2104 | 0.2171 | 0.1863 | 0.0807 | 39.038 | 12.507 | 5.6486 | 2.1661 | |
| rayleigh_taylor_instability | 0.1714 | 0.1351 | — | 0.0491 | 3.0057 | 5.3894 | — | 0.5862 | |
| shear_flow | 0.0769 | 0.0594 | 0.1093 | 0.0463 | 1.1245 | 0.7632 | 0.8930 | 0.2246 | |
| supernova_explosion | 0.4326 | 0.4316 | — | 0.2888 | 1.0162 | 2.2913 | — | 0.8113 | |
| turbulence_gravity_cooling | 0.2720 | 0.2113 | — | 0.1700 | 3.2583 | 2.0510 | — | 1.2636 | |
| turbulent_radiative_layer_2D | 0.3250 | 0.2559 | 0.3555 | 0.1930 | 1.2328 | 0.7051 | 0.8299 | 0.5491 | |
| turbulent_radiative_layer_3D | 0.3261 | 0.3322 | — | 0.2073 | 0.9203 | 0.7139 | — | 0.6840 | |
| viscoelastic_instability† | 0.1914 | 0.1623 | 0.2017 | 0.0624 | 0.4284 | 0.3592 | 0.4890 | 0.3465 | |
| PDEBench | Diffusion-Reaction | 0.0191 | 0.0033 | 0.0150 | 0.0015 | 0.7563 | 0.0279 | 0.0949 | 0.0241 |
| Shallow Water | 0.0019 | 0.0044 | 0.0187 | 0.0010 | 0.2499 | 0.1427 | 0.1164 | 0.0076 | |
Table 1. VRMSE for unconditioned 4→1 next-step prediction and 1:20 autoregressive rollout.
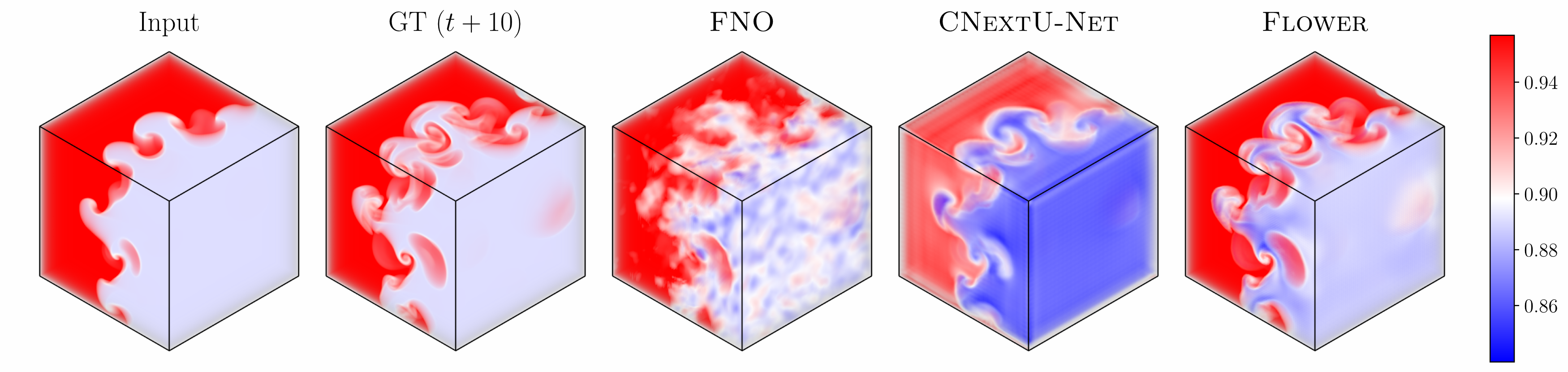
3D Rayleigh–Taylor instability: 10-step autoregressive prediction of density. Because displacements are predicted pointwise, Flower scales naturally to 3D with a cost that is linear in the number of grid points.
Interpretability
Without any explicit supervision on flow direction, the warp field aligns with the underlying fluid velocity: the model learns to look upstream along characteristics, exactly as conservation law theory would suggest.

Learned displacement fields on shear flow. The black arrows show the displacement field predicted by the first head of the first downsampling block, overlaid on the tracer field.
Scaling
We scale Flower from 17M to 156M parameters on the compressible Euler equations dataset and compare against Poseidon-L, a 628M-parameter foundation model pretrained on diverse fluid-dynamics. All Flower variants are trained from scratch. Performance improves smoothly with model size, and even Flower-Tiny matches Poseidon-L on the 1:20 rollout.
| Model | Parameters | 1-Step ↓ | 1:20 Rollout ↓ |
|---|---|---|---|
| Flower-Tiny | 17.3M | 0.0160 | 0.1114 |
| Flower-Small | 69.3M | 0.0124 | 0.0850 |
| Flower-Medium | 155.8M | 0.0108 | 0.0739 |
| Poseidon-L (pretrained) | 628.6M | 0.0194 | 0.1114 |
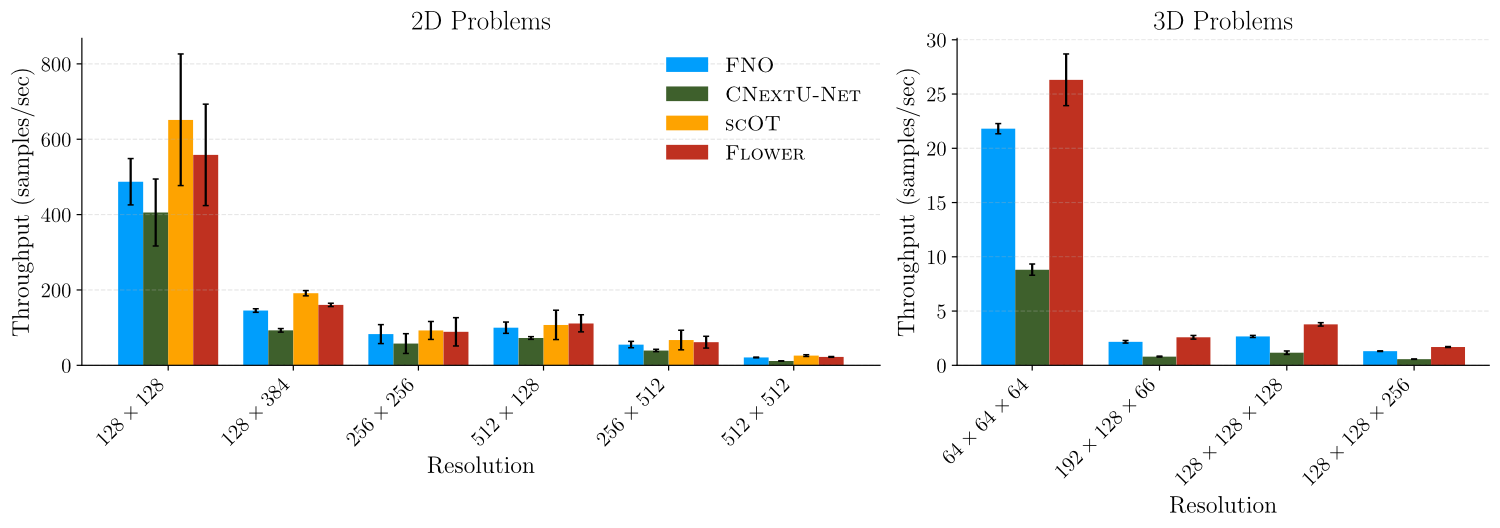
Computational Efficiency/Throughput
Accuracy improvements would be of limited use if they came at significant compute cost. Flower matches the throughput of FNO and scOT across resolutions, while substantially outperforming CNUnet, especially in 3D, where pointwise displacement prediction gives Flower a natural efficiency advantage.